Besides the robots the robolab contains a camera overlooking a specific region in the robolab of about 1m x 1.5m. This camera is connected to a computer, which also has a radio communication module to communicate with the robots.


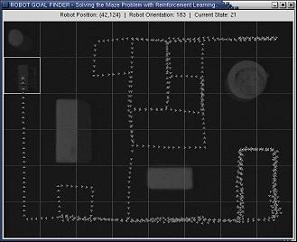
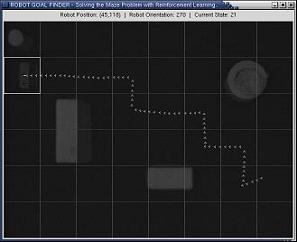
In order to perform reinforcement learning a robot driving through the environment has to know its location. Due to inaccuracies in the driving of robots it is not a trivial task to obtain an accurate location estimate. One way to do deal with this is by using Kalman filters as I describe in my Master's thesis. In this project however we assume that a robot has access to its location through some sort of GPS system. We used the hat with lights that we specifically designed for tracking the robot through the images made by the top camera, analyzed by the computer. Once the computer had detected a robot it used the radio communication to communicate this location with the robot.